LIPS - Learning Industrial Physical Simulation
Benchmarking framework to evaluate AI-based physical simulation

Physical simulations are at the core of many critical industrial systems. However, today's physical simulators have some limitations such as computation time, dealing with missing or uncertain data, or even non-convergence for some feasible cases. Recently, the use of data-driven approaches to learn complex physical simulations has been considered as a promising approach to address those issues. However, this comes often at the cost of some accuracy which may hinder the industrial use.
# What is LIPS
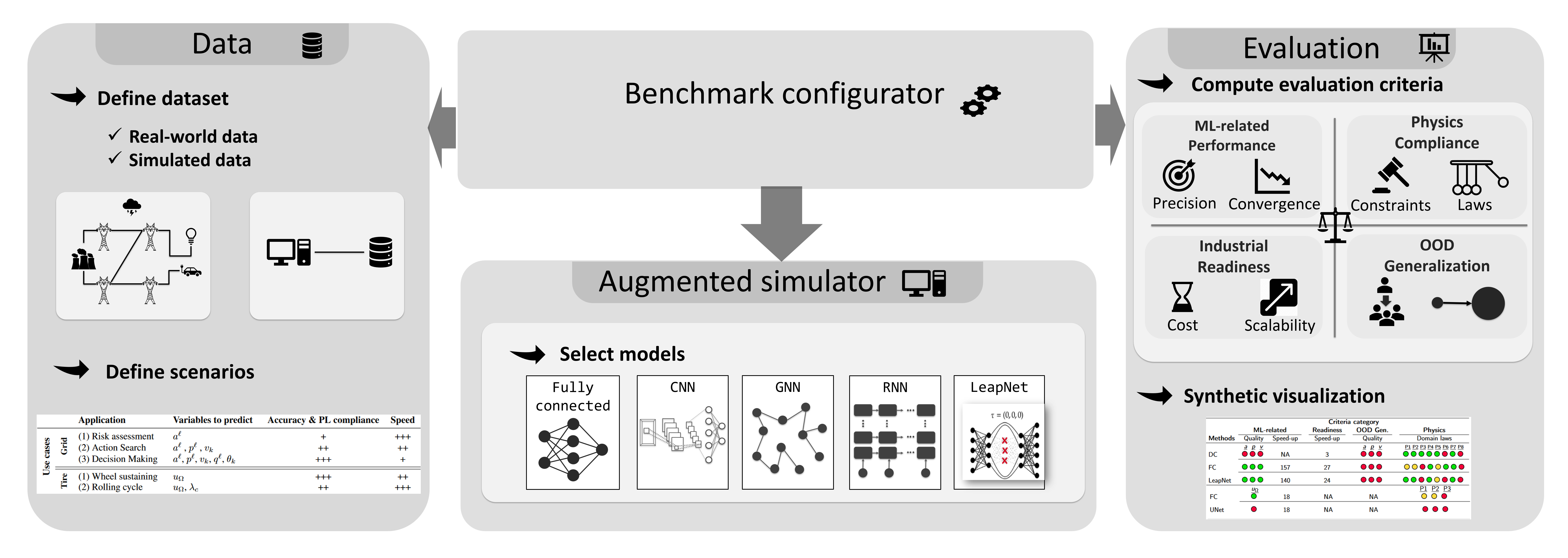
To drive the above mentioned new research topic towards a better real-world applicability, we propose a new benchmark suite "Learning Industrial Physical Simulations" (LIPS) to meet the need of developing efficient, industrial application-oriented, augmented simulators. The proposed benchmark suite is a modular and configurable framework that can deal with different physical problems. To do so, as it is depicted in the scheme, the LIPS platform is designed to be modular and includes following modules:
Data: This module may be used to import the required datasets or to generate some synthetic data using physical solvers;
Augmented Simulator: This module offers a list of already implemented data-driven models which could be used to augment or to substitute the physical solvers. The datasets imported using
Datamodule may be used to learn these models;Benchmark configurator: This module takes a dataset related to a specific task and usecase, an already trained augmented simulator (aka model) and a set of metrics and call the evaluator module to assess the performance of the model;
Evaluation: This module is responsible to evaluate the performance of a selected benchmark. To define how to assess such benchmark performance, we propose a set of four generic categories of criteria:
ML-related metrics: Among classical ML metrics, we focus on the trade-offs of typical model accuracy metrics such as Mean Absolute Error (MAE) vs computation time (optimal ML inference time without batch size consideration as opposed to application time later);
Physics compliance: Physical laws compliance is decisive when simulation results are used to make consistent real-world decisions. Depending on the expected level of criticality of the benchmark, this criterion aims at determining the type and number of physical laws that should be satisfied;
Industrial readiness: When deploying a model in real-world applications, it should consider the real data availability and scale-up to large systems.
Application-based out-of-distribution (OOD) generalization: For industrial physical simulation, there is always some expectation to extrapolate over minimal variations of the problem geometry depending on the application.
# Synthetic results
To demonstrate this ability, we propose in this paper to investigate two distinct use-cases with different physical simulations, namely: Power Grids, Pneumatics and Air Foils. For each use case, several benchmarks (aka tasks or scenarios) may be described and assessed with existing models. In the figure below, we show an example of the results obtained for a specific task associated with each use case. To ease the reading of the numerical comparison table, the performances are reported using three colors computed on the basis of two thresholds. The meaning of colors is described below:
- Great: Designates the best performance that could be obtained for a metric and an associated variable. The metric value should be lower than the first threshold;
- Acceptable: Designates an acceptable performance that could be obtained for a metric and an associated variable. The metric value should be between the first and the second thresholds;
- Not acceptable: Designates a not acceptable performance using a metric and an associated variable. The metric value should higher than the second threshold.
The number of circles corresponds to the number of variables or laws that are evaluated.
The table bellow summarizes the evaluation scores for three distinct physical use cases namely : the power grid, the tire rolling and the airfoil design. We can see that none of the models perform well under all expected criteria, inviting the community to develop new industry-applicable solutions and possibly showcase their performance publicly upon online LIPS instance on Codabench.

The final score is computed on the basis of the obtained results for each metric.
# Documentation
The LIPS platform documentation (opens new window)
Published paper (opens new window)
# Github Repository
The LIPS platform is open source and is accessible via Github Repository (opens new window).


